How to Build a Plagiarism Detector [Part 2] – Semantic Search
In this post, I will show you a better approach to building a Plagiarism detector tool, other than the one we built last time which checks for exact matches on the Internet.
Today’s method will check for plagiarism based on how close the meaning and sentence structure are rather than searching for exact matches. This will help detect paraphrased text in addition to copy-pasted text.
We will go over 4 approaches, where we will compare articles as a whole and as chunks. Each approach will be applied using AI and vector embeddings, resulting in the following 4 approaches:
Method 1: Comparing chunks of both articles using vector embeddings
Method 2: Comparing 2 articles as a whole using vector embeddings
Method 3: Comparing chunks of both articles using AI
Method 4: Comparing 2 articles as a whole using AI
What are Vector Embeddings?
If you know what vector embeddings are, feel free to skip this section.
Vector Embedding is one of the most important concepts in machine learning. It is used in many NLP, recommendation, and search algorithms.
It enables computers to understand and process complex data, such as text, images, and more, in a more human-like manner.
By representing objects or words as high-dimensional vectors (points in space), embeddings capture their meanings, relationships, and properties in a way that numerical algorithms can manipulate.
So, all words/phrases/paragraphs with similar meanings are positioned closely together in the embedding space, allowing models to recognize patterns and make predictions.
In our case, we’ll use vector embeddings to generate high-dimensional vectors for pieces of text. Then, using something called cosine similarity, we’ll know if the texts are similar in meaning and structure.
💡 Tip 💡 Make sure to go over part 1 and apply the simpler implemention to understand how plagiarism checkers work to navigate easily through this one.
The Implementations
I’m gonna go over each implementation briefly, explaining the idea, and in the end, I’m gonna compare all the results we got and analyze them. (I’ll share all the resources I used at the end don’t worry )
For more accurate results and analysis, and to make things easier, I won’t be surfing the web and comparing my pieces of text with pieces on the web as we did in the first part. But I’ll use 2 pieces of text that are close in meaning to each other I got, and I’ll apply all the methods to them.
After understanding how these methods all work, you can then add the search function to your code, which I mentioned in part 1, and you’ll have your own custom semantic Plagiarism Checker!
Method 1: Comparing Chunks Using Vector Embeddings
The idea of this approach is I’m gonna split the article we want to test and the article we’re comparing it to into chunks, where the chunking method used is by-paragraph.
Then I’m gonna turn all these chunks into vector embeddings using OpenAI’s “text-embedding-3-small” model, and I’ll compare each chunk from the input article with all chunks in the other article, using the cosine similarity function, giving it a threshold of 0.7
This threshold will be used to compare the output of the cosine similarity to it. If the cosine similarity is greater than 0.7, then the 2 vectors are similar in meaning and, therefore, plagiarised. The threshold I chose is just for testing; if you want to apply a more accurate one, you’ll have to do your own research to know what threshold would be the best in this case.
from SimplerLLM.tools.text_chunker import chunk_by_paragraphs
from scipy.spatial.distance import cosine
import time
import resources
import openai
def search_semantically_similar(text):
"""
This function takes a piece of text and calculates its plagiarism score
against another text by comparing the semantic similarity of their chunks.
"""
chunks = chunk_by_paragraphs(text) # Divide the input text into chunks/paragraphs
article_paragraphs = chunk_by_paragraphs(resources.article_two) # Divide the second text into chunks/paragraphs for comparison
all_comparisons = 0 # Initialize a counter for all comparison attempts
plagiarised_chunks = 0 # Initialize a counter for chunks found to be plagiarised based on similarity threshold
for chunk in chunks.chunks: # Iterate over each chunk in the first text
chunk_vector = convert_to_vector(chunk.text) # Convert the chunk text to a vector using an embedding model
for paragraph in article_paragraphs.chunks: # Iterate over each paragraph in the second text
if paragraph.text.strip(): # Ensure the paragraph is not just whitespace
all_comparisons += 1 # Increment the total comparisons counter
paragraph_vector = convert_to_vector(paragraph.text) # Convert the paragraph text to a vector
similarity = calculate_cosine_similarity(chunk_vector, paragraph_vector) # Calculate the cosine similarity between vectors
if is_similarity_significant(similarity): # Check if the similarity score is above a certain threshold
plagiarised_chunks += 1 # If so, increment the count of plagiarised chunks
plagiarism_score = ((plagiarised_chunks / all_comparisons) * 100) # Calculate the percentage of chunks considered plagiarised
return plagiarism_score # Return the plagiarism score
def convert_to_vector(text):
"""
Converts a given piece of text into a vector using OpenAI's embeddings API.
"""
text = text.replace("\n", " ") # Remove newlines for consistent embedding processing
response = openai.embeddings.create(
input=[text],
model="text-embedding-3-small"
)
return response.data[0].embedding # Return the embedding vector
def calculate_cosine_similarity(vec1, vec2):
"""
Calculates the cosine similarity between two vectors, representing the similarity of their originating texts.
"""
return 1 - cosine(vec1, vec2) # The cosine function returns the cosine distance, so 1 minus this value gives similarity
def is_similarity_significant(similarity_score):
"""
Determines if a cosine similarity score indicates significant semantic similarity, implying potential plagiarism.
"""
threshold = 0.7 # Define a threshold for significant similarity; adjust based on empirical data
return similarity_score >= threshold # Return True if the similarity is above the threshold, False otherwise
#MAIN SECTION
start_time = time.time() # Record the start time of the operation
text_to_check = resources.article_one # Assign the text to check for plagiarism
plagiarism_score = search_semantically_similar(text_to_check) # Calculate the plagiarism score
end_time = time.time() # Record the end time of the operation
runtime = end_time - start_time # Calculate the total runtime
# Output the results
print(f"Plagiarism Score: {plagiarism_score}%") # Print the calculated plagiarism score
print(f"Runtime: {runtime} seconds") # Print the total runtime of the script
As you can see in the above code, in the main section, we’re giving it the text_to_check, which will be run using the search_semantically_similar function, which, in its role, goes over all the steps I mentioned above.
In the codes, I’ll be using the SimplerLLM library I built to facilitate and speed up the coding process. In these implementations, I’ll be using it to generate text using OpenAI’s API(methods 3 and 4) and chunk text by paragraphs using this simple function:
chunks = chunk_by_paragraphs(text)
Other than that, the code should be simple to read and understand, given all the comments I added throughout the code😅 However, in case you found something unclear and you need some help, don’t hesitate to drop your questions on the forum!
Method 2: Comparing 2 articles as a whole using vector embeddings
In this method, we’ll be directly comparing both articles as a whole without chunking them by converting both of them into vector embeddings. Then, using cosine similarity, we’ll see if they’re similar to each other.
from scipy.spatial.distance import cosine
import time
import resources
import openai
def convert_to_vector(text):
"""
Converts a given piece of text into a vector using OpenAI's embeddings API.
"""
text = text.replace("\n", " ") # Remove newlines for consistent embedding processing
response = openai.embeddings.create(
input=[text],
model="text-embedding-3-small"
)
return response.data[0].embedding # Return the embedding vector
def calculate_cosine_similarity(vec1, vec2):
"""
Calculates the cosine similarity between two vectors, representing the similarity of their originating texts.
"""
return 1 - cosine(vec1, vec2) # The cosine function returns the cosine distance, so 1 minus this value gives similarity
def is_similarity_significant(similarity_score):
"""
Determines if a cosine similarity score indicates significant semantic similarity, implying potential plagiarism.
"""
threshold = 0.7 # Define a threshold for significant similarity; adjust based on empirical data
return similarity_score >= threshold # Return True if the similarity is above the threshold, False otherwise
def search_semantically_similar(text_to_check):
"""
Compares the semantic similarity between the input text and a predefined article text.
It returns a list containing the similarity score and a boolean indicating whether
the similarity is considered significant.
"""
result = [] # Initialize an empty list to store the similarity score and significance flag
input_vector = convert_to_vector(text_to_check) # Convert the input text to a vector using an embedding model
article_text = resources.article_two # texts.two contains the text of the article to compare with
article_vector = convert_to_vector(article_text) # Convert the article text to a vector
similarity = calculate_cosine_similarity(input_vector, article_vector) # Calculate the cosine similarity between the two vectors
result.append(similarity) # Append the similarity score to the list
result.append(is_similarity_significant(similarity)) # Append the result of the significance check to the list
return result # Return the list containing the similarity score and significance flag
def calculate_plagiarism_score(text):
"""
Calculates the plagiarism score of a given text by comparing its semantic similarity
with a predefined article text. The score is expressed as a percentage.
"""
data = search_semantically_similar(text) # Obtain the similarity data for the input text
data[0] = data[0] * 100 # Convert the first item in the data list (similarity score) to a percentage
return data # Return the plagiarism score and significance
#MAIN SECTION
start_time = time.time() # Record the start time of the operation
text_to_check = resources.article_one # Assign the text to check for plagiarism
plagiarism_score = calculate_plagiarism_score(text_to_check)[0]
significance = calculate_plagiarism_score(text_to_check)[1]
end_time = time.time() # Record the end time of the operation
runtime = end_time - start_time # Calculate the total runtime
# Output the results
print(f"Plagiarism Score: {plagiarism_score}%") # Print the calculated plagiarism score
print(f"Is result Significant: {significance}") # Print the signficance of the score
print(f"Runtime: {runtime} seconds") # Print the total runtime of the script
As you can see, the code is very similar in structure to method 1. However, the search_semantically_similar function was edited to directly turn both articles into vectors, compare them, and return the result without chunking.
Plus, I added the calculate_plagiarism_score function, which takes the similarity score and generates a percentage of it. Then, it will return the percentage score and True/False statement if the plagiarism score is significant, which will be analyzed by comparing the cosine similarity score with the threshold I initiated to be 0.7
Method 3: Comparing chunks of both articles using AI
Now it’s time for AI to enter the battlelfield😂
This method is the same as method 1 in concept; however, instead of comparing the chunks by embedding them into vectors and generating the cosine similarity, we’ll compare them using a power prompt and OpenAI’s GPT model.
from SimplerLLM.tools.text_chunker import chunk_by_paragraphs
from SimplerLLM.language.llm import LLM, LLMProvider
import time
import resources
import json
def compare_chunks(text_chunk):
"""
Compares a text chunk with an article text and generates a response using a OpenAI's Model
"""
article_text = resources.article_two # The text to compare against
prompt = resources.prompt3 # A template string for creating the comparison prompt
final_prompt = prompt.format(piece=text_chunk, article=article_text) # Formatting the prompt with the chunk and article texts
llm_instance = LLM.create(provider=LLMProvider.OPENAI) # Creating an instance of the language model
response = llm_instance.generate_text(final_prompt) # Generating text/response from the LLM
response_data = json.loads(response) # Parsing the response into a JSON object
return response_data # Returning the parsed response data
def calculate_plagiarism_score(text):
"""
Calculates the plagiarism score of a text by comparing its chunks against an article text
and evaluating the responses from OpenAI's Model
"""
text_chunks = chunk_by_paragraphs(text) # Split the input text into chunks using SimplerLLM built-in method
total_chunks = text_chunks.num_chunks # The total number of chunks in the input text
similarities_json = {} # Dictionary to store similarities found
chunk_index = 1 # Index counter for naming the chunks in the JSON
plagiarised_chunks_count = 0 # Counter for the number of chunks considered plagiarised
total_scores = 0 # Sum of scores from the LLM responses
for chunk in text_chunks.chunks:
response_data = compare_chunks(chunk.text) # Compare each chunk using the LLM
total_scores += response_data["score"] # Add the score from this chunk to the total scores
if response_data["score"] > 6: # A score above 6 indicates plagiarism
plagiarised_chunks_count += 1
similarities_json[f"chunk {chunk_index}"] = response_data["article"] # Record the article text identified as similar
json.dumps(similarities_json) # Convert the JSON dictionary to a string for easier storage
chunk_index += 1 # Increment the chunk index
plagiarism_result_json = {} # Dictionary to store the final plagiarism results
plagiarism_score = (plagiarised_chunks_count / total_chunks) * 100 if total_chunks > 0 else 0 # Calculate the plagiarism score as a percentage
plagiarism_result_json["Score"] = plagiarism_score
plagiarism_result_json["Similarities"] = similarities_json # Adding where we found similaritites
plagiarism_result_json["IsPlagiarised"] = (total_scores > total_chunks * 6) # Recording if the response is really plagiarised
json.dumps(plagiarism_result_json) # Convert the final results dictionary to a JSON string
return plagiarism_result_json # Return the plagiarism results as a dictionary
#MAIN SECTION
start_time = time.time() # Record the start time of the operation
text_to_check = resources.article_one # Assign the text to check for plagiarism
plagiarism_score = calculate_plagiarism_score(text_to_check)
formatted_plagiarism_score = json.dumps(plagiarism_score, indent=2) # Format the output for better readability
end_time = time.time() # Record the end time of the operation
runtime = end_time - start_time # Calculate the total runtime
# Output the results
print(f"Plagiarism Score: {formatted_plagiarism_score}") # Print the calculated plagiarism score
print(f"Runtime: {runtime} seconds") # Print the total runtime of the script
In the code, the main function is the calculate_plagiarism_score, which chunks the articles, sends them to the compare_chunks function to get the similarity score, generates a total plagiarism score, and formats the results as JSON to add some details other than the plagiarism score, keeping them clear and readable.
The compare_chunks function creates a GPT instance using SimplerLLM, then uses a power prompt to analyze both chunks and generate a score out of 10 for how similar they are. Here’s the prompt I’m using:
#TASK
You are an expert in plagiarism checking. Your task is to analyze two pieces of text, an input chunk,
and an article. Then you're gonna check if there are pieces of the article that are similar in meaning to
the input chunk. After that you're gonna pick the piece of article which is most similar and generate for it
a score out of 10 for how similar it is to the input chunk. Then you're gonna need to generate the output
as a JSON format that contains the input chunk, the article chunk which is the most similar, and the score
out of 10.
### SCORING CRITERIA
When checking for pieces in the article that are close in meaning to the chunk of text make sure you
go over the article at least 2 times to make sure you picked the the right chunk in the article which is the most
similair to the input chunk. Then when picking a score it should be based of how similar are the meanings
and structure of both these sentences.
# INPUTS
input chunk: [{piece}]
article: [{article}]
# OUTPUT
The output should be only a valid JSON format nothing else, here's an example structure:
{{
"chunk": "[input chunk]",
"article": "[chunk from article which is similar]",
"score": [score]
}}As you can see, it is a detailed prompt, very well crafted to generate a specific result. You can learn how to craft similar prompts yourself by becoming a Prompt Engineer.
Method 4: Comparing 2 articles as a whole using AI
This method is a combination of methods 2 and 3, where we’re gonna be comparing both articles as a whole but using AI instead of vector embeddings.
from SimplerLLM.language.llm import LLM, LLMProvider
import time
import resources
import json
def compare_chunks(text_chunk):
"""
Compares a given text chunk with an article to determine plagiarism using a language model.
Returns dict: The response from the language model, parsed as a JSON dictionary.
"""
article_text = resources.article_two # The text to compare against
# Formatting the prompt to include both the input text chunk and the article text
comparison_prompt = resources.prompt4.format(piece=text_chunk, article=article_text)
llm_instance = LLM.create(provider=LLMProvider.OPENAI) # Creating an instance of the language model
response = llm_instance.generate_text(comparison_prompt) # Generating response
response_data = json.loads(response) # Parsing the response string into a JSON dictionary
return response_data # Returning the parsed JSON data
def calculate_plagiarism_score(text_to_analyze):
"""
Calculates the plagiarism score based on the analysis of a given text against a predefined article text.
Returns dict: A JSON dictionary containing the plagiarism score and the raw data from the analysis.
"""
plagiarism_results = {} # Dictionary to store the final plagiarism score and analysis data
plagiarised_chunk_count = 0 # Counter for chunks considered plagiarised
analysis_data = compare_chunks(text_to_analyze) # Analyze the input text for plagiarism
total_chunks = len(analysis_data) # Total number of chunks analyzed
for key, value in analysis_data.items():
# Check if the value is a list with at least one item and contains a 'score' key
if isinstance(value, list) and len(value) > 0 and 'score' in value[0] and value[0]['score'] > 6:
plagiarised_chunk_count += 1
# Check if the value is a dictionary and contains a 'score' key
elif isinstance(value, dict) and 'score' in value and value['score'] > 6:
plagiarised_chunk_count += 1
plagiarism_score = (plagiarised_chunk_count / total_chunks) * 100 if total_chunks > 0 else 0 # Calculate plagiarism score as a percentage
plagiarism_results["Total Score"] = plagiarism_score # Add the score to the results dictionary
plagiarism_results["Data"] = analysis_data # Add the raw analysis data to the results dictionary
json.dumps(plagiarism_results) # Convert the results dictionary to a clear JSON string
return plagiarism_results # Return the final results dictionary
#MAIN SECTION
start_time = time.time() # Record the start time of the operation
text_to_check = resources.article_one # Assign the text to check for plagiarism
plagiarism_score = calculate_plagiarism_score(text_to_check)
formatted_plagiarism_score = json.dumps(plagiarism_score, indent=2) # Format the output for better readability
end_time = time.time() # Record the end time of the operation
runtime = end_time - start_time # Calculate the total runtime
# Output the results
print(f"Plagiarism Score: {formatted_plagiarism_score}") # Print the scores
print(f"Runtime: {runtime} seconds") # Print the total runtime of the script
This code is 80% like the code in method 3. However, instead of comparing each chunk, we send both articles as a whole and let OpenAI’s GPT generate a detailed plagiarism test, comparing all parts of the articles as it wishes. In the end, it returns a detailed output containing a plagiarism score and the top sections are found to be similar in their similarity score.
All this is done using this power prompt:
### TASK
You are an expert in plagiarism checking. Your task is to analyze two pieces of text, an input text,
and an article. Then you're gonna check if there are pieces of the article that are similar in meaning to
the pieces of the input text. After that you're gonna pick chunk pairs that are most similar to each other
in meaning and structure, a chunk from the input text and a chunk from the article. You will then generate
a score out of 10 for each pair for how similar they are.
Then you're gonna need to generate the output as a JSON format for each pair that contains
the input text chunk, the article chunk which are the most similar, and the score out of 10.
### SCORING CRITERIA
When checking for peices in the article that are close in meaning to the chunk of text make sure you
go over the article at least 2 times to make sure you picked the right pairs of chunks which are most similar.
Then when picking a score it should be based of how similar are the meanings and structure of both these sentences.
### INPUTS
input text: [{piece}]
article: [{article}]
### OUTPUT
The output should be only a valid JSON format nothing else, here's an example structure:
{{
"pair 1":
[
"chunk 1": "[chunk from input text]",
"article 1": "[chunk from article which is similar]",
"score": [score]
],
"pair 2":
[
"chunk 2": "[chunk from input text]",
"article 2": "[chunk from article which is similar]",
"score": [score]
],
"pair 3":
[
"chunk 3": "[chunk from input text]",
"article 3": "[chunk from article which is similar]",
"score": [score]
],
"pair 4":
[
"chunk 4": "[chunk from input text]",
"article 4": "[chunk from article which is similar]",
"score": [score]
]
}}The prompt in methods 3 and 4 is very important to be well-crafted since all the results are based on it. Feel free to tweak and optimize it to your liking and if it generates better results make sure to share it with us in the comments below!
Method 5: My Opinion
After we tried 2 types of machines to do the work for us, let’s now use human intelligence and see if their results are significant!
Here are the 2 texts I was comparing:
Article 1:
What is generative AI?
Generative AI refers to deep-learning models that can generate high-quality text, images, and other content based on the data they were trained on.
Artificial intelligence has gone through many cycles of hype, but even to skeptics, the release of ChatGPT seems to mark a turning point. OpenAI's chatbot, powered by its latest large language model, can write poems, tell jokes, and churn out essays that look like a human created them.
Prompt ChatGPT with a few words, and out comes love poems in the form of Yelp reviews, or song lyrics in the style of Nick Cave.Article 1:
What is generative AI?
Generative artificial intelligence (AI) describes algorithms (such as ChatGPT) that can be used to create new content, including audio, code, images, text, simulations, and videos.
Recent breakthroughs in the field have the potential to drastically change the way we approach content creation.
Generative AI systems fall under the broad category of machine learning, and here's how one such system—ChatGPT—describes what it can do:
Ready to take your creativity to the next level? Look no further than generative AI!
This nifty form of machine learning allows computers to generate all sorts of new and exciting content, from music and art to entire virtual worlds. And it's not just for fun—generative AI has plenty of practical uses too, like creating new product designs and optimizing business processes. So why wait? Unleash the power of generative AI and see what amazing creations you can come up with!
Did anything in that paragraph seem off to you? Maybe not. The grammar is perfect, the tone works, and the narrative flows.As you can both articles are about the same topic and they’re just a small chunk of it, so it’s something logical for the plagiarism score to be at least 50% if not 80%. Read both of them, and you’ll see they’re very close; they were just written in different styles.
Therefore, to get more accurate results and see which of the methods is the best among them, we’ll need to run all of them on 10-20 pairs of long articles.
Of course, I can’t do that in this blog and share all the results. It would take forever😂 So, I’ll keep the experimentation for you and share the results with us!
Run The Codes
To run the codes, you’re gonna have to create a .env file that contains your OpenAI API key like this:
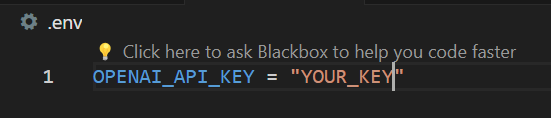
This way, all the methods will run perfectly, but using the articles I presented above. If you wish to input your own articles, you will find them in the resources.py file along with both power prompts I mentioned above.
Plus, don’t forget to install all the necessary libraries, which you will find in the requirements file. Install them by running this in the terminal:
pip install -r requirements.txt
Comparison
I executed all the methods on the same set of articles I presented above, and here were the results:
| Factors | Method 1 | Method 2 | Method 3 | Method 4 |
|---|---|---|---|---|
| Plagiarism Score | 25% | 85% | 100% | 100% |
| Runtime | 44 secs | 1 sec | 8 secs | 10 secs |
Runtime analysis
Logically, Methods 1 and 3 are supposed to take more time than Methods 2 and 4 because they compare all chunks rather than the articles as a whole. However, the runtime of method 1 is very bad, so to use this method, you’re gonna either need to optimize the code to run faster (ex: parallel programming)
Other than that, all runtimes are good, so there is no need to optimize any of the other codes.
Plagiarism Score Analysis
I’ll give my personal analysis of each method and then draw a full conclusion.
Method 1:
25% for these 2 articles is very low, considering they’re very similar in meaning. However, I hypothesize that since each chunk is being compared to all other chunks, it’s something logical that not all parts of the article are gonna be about the same idea.
So, when we’re comparing, for example, a chunk in paragraph 1 and a chunk in the last paragraph, of course, these chunks would be about totally different ideas. Plus, the probability for a pair to be similar is way lower than that of being about a different idea because, in each article, every idea is mentioned once, so only one chunk will have a very similar meaning to the chunk we’re comparing.
However, this method has a major drawback: where if in one article we have a paragraph and in the other article we have exactly the same paragraph but split into 2, it won’t detect that they’re the same. That’s because we’re chunking based on paragraphs so in article 2 the 2 paragraphs would be 2 different chunks while in article 1 they would be 1 chunk, therefore affecting the score. To solve this, we need a better chunking method!
Method 2:
A score of 85% is very fair for such articles; they are truly very similar. However, do you think comparing 2 articles as a whole is really efficient to test for plagiarism? Personally, I don’t think it’s a good practice to use it since the purpose of plagiarism detection is to check for parts of articles that are found on the internet.
In this case, it will only work if both articles are the exact same copies from the introduction to the conclusion, giving a 100% accurate result.
Methods 3 and 4:
These 2 methods are kinda the same because in the background, both of them are using AI to go over different chunks and check which pairs are the most similar. However, the main difference is that in 3 we are manually chunking the articles by paragraph, while in 4 the AI is doing it as it finds the most efficient, so we can’t actually tell how it is chunking the articles.
In addition, these methods totally rely on how well-crafted the prompt is, so you can get better results by improving it and vice versa. The main factor that determines how good the prompt is, is making it apply the best plagiarism algorithm possible, where you’re gonna have to do your own research understand the algorithm, and implement it in a well-crafted prompt.
Conclusion
There is no actual conclusion; it’s more of an opinion.
Based on the tests I did, I can say that method 1 might be the best way to implement a good plagiarism checker because it goes into detail about all the chunks of the articles and compares them. So, with a better chunking method and more optimized code to make it faster, I think it would make a good plagiarism checker!
Agree or Disagree? Share your thoughts in the comments section!
Hmm… maybe a score should be presented as a mean average score of the four methods. This could be a more accurate representation of plagiarism. In this case the mean average is 77.5% ((25% + 85% + 100% + 100%) / 4). What do you think about this?