Get Consistent Structured JSON From Gemini with Python
In this post, I will show you how to generate consistent JSON responses from Google Gemini using Python. No fluff… a direct, practical solution I created, Tested, and Worked!
My approach is super simple and acts as a perfect starting point to deal with consistent responses in Langauge models, at least in my opinion 🙂
I will explain the approach step by step with a practical example and then show you my magical tweak, which can save you countless hours!
Let’s Start!
Understand The Problem
When working with Language Models like Google Gemini, it can be challenging to get a structured and consistent JSON response every time you ask for something.
For example:
If I ask Google Gemini to generate a list of blog post titles and return a JSON, we will get something like this:
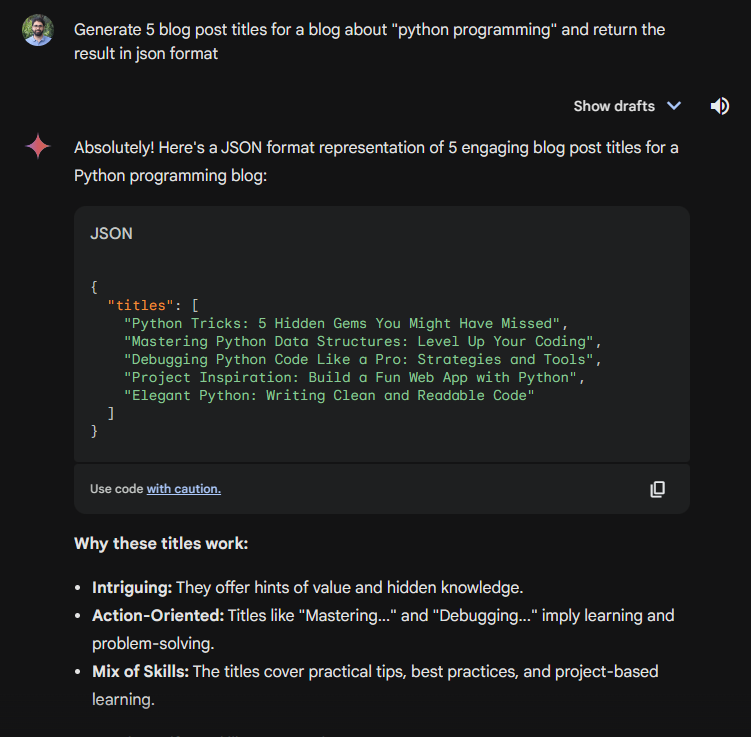
Let’s ask it again with the same prompt… and we get this:
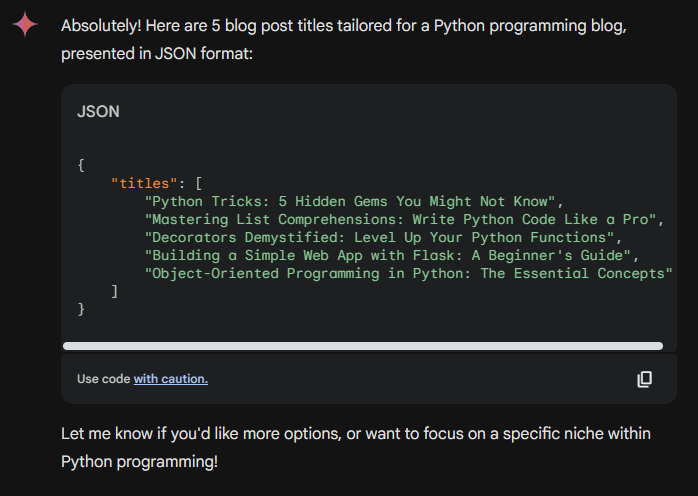
Yeah, we got JSON, but with a lot of text! And with different responses each time.
No Consistency! So what? What is the problem with this response?
The main issue here is when we want to use the output of the LLM (in our case, Gemini) to build tools and applications.
Let me show you an example of a tool I built: The Hook Generator Tool
This is how it works:
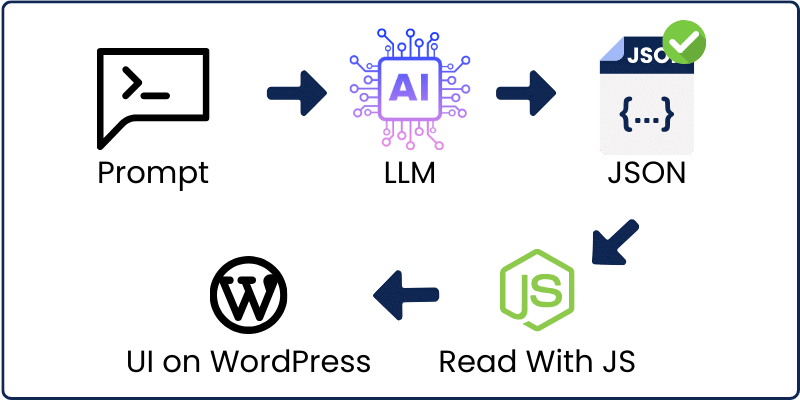
So, I create a prompt that generates Hooks—not any prompt, but a Power prompt based on data. (not our topic for today)
I pass the prompt to the language model, and I get a JSON response. Then, I read the JSON with Javascript and populate the UI on WordPress.
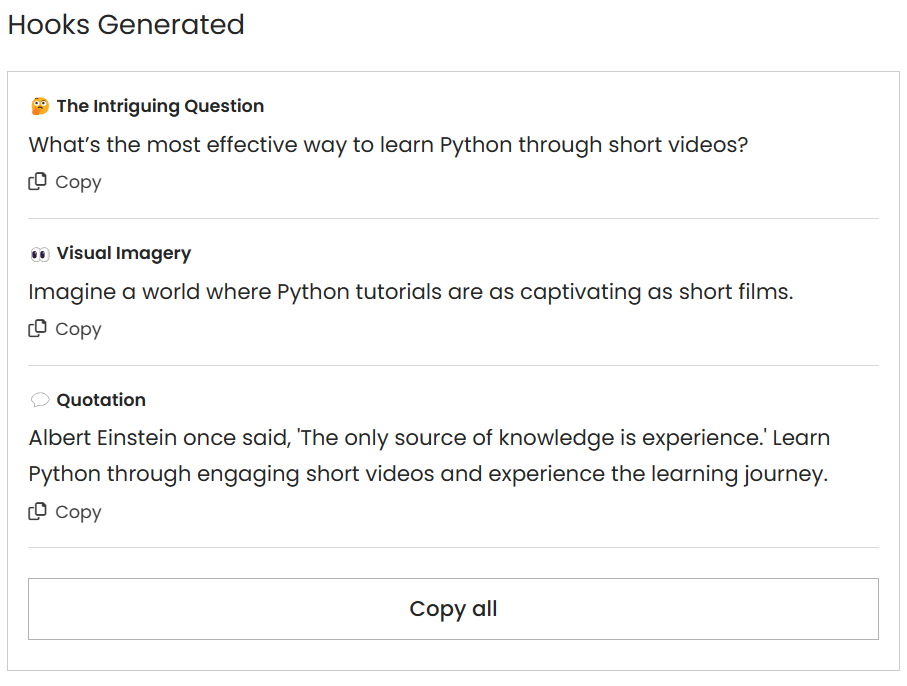
Here is a sample JSON I got from the LLM for my tool:
[
{
"hook_type": "The Intriguing Question",
"hook": "What’s the most effective way to learn Python through short videos?"
},
{
"hook_type": "Visual Imagery",
"hook": "Imagine a world where Python tutorials are as captivating as short films."
},
{
"hook_type": "Quotation",
"hook": "Albert Einstein once said, 'The only source of knowledge is experience.' Learn Python through engaging short videos and experience the learning journey."
}
]And based on that, I can build a UI like this:
🔥 If you are interested in learning how to build this AI tool step by step and monetize with the credit system, as I do here on my website with my tools, to turn WordPress into SaaS, you can check out my courses here.
Anyway, getting back to our problem, did you spot it? 🤔
Yes, it is in JSON. To build tools like this, we must ensure that we get the same JSON response from the language model every time.
If we get a different JSON, it will be impossible to have a consistent UI for the tool because we will not be able to parse and read the response with Javascript or any language you are using. (even with no code)
There are several ways and approaches to solve this issue and achieve consistent JSON response.
Starting with some prompting techniques that force the model to generate a response based on the example output you provide, something like this:
IMPORTANT: The output should be a JSON array of 10 titles without field names. Just the titles! Make Sure the JSON is valid.
Example Output:
[
"Title 1",
"Title 2",
"Title 3",
"Title 4",
"Title 5",
"Title 6",
"Title 7",
"Title 8",
"Title 9",
"Title 10",
]Another approach is using Function calling with OpenAI Models or Python Instructor Package with Pydantic, which is also limited to OpenAI and relies on Function calling.
I also automated and simplified the process of building AI tools fast in this blog.
To learn more about this problem and suggested solutions, you can check out this blog post I wrote on function chaining.
🟢 But what about a generic approach that works with any model and does not rely solely on a specific model or functionality?
You CAN’T build all your tools and apps relying on one feature or model.
It is better to take a more dynamic approach so that you can switch from model to model at any time without changing your full codes and structure.
With this said, I thought of a way, and I came up with a basic yet powerful approach that got me the results I wanted: consistent JSON response!
My Solution!
Let’s keep things simple with a real practical example!
Let’s say you want to build a Simple Blog Title Generator Tool, maybe like this one.
Here is what we need:
1- Craft a Prompt that Generate Blog Post Titles.
2- Feed the prompt to Google Gemini or other language models.
3- Get JSON Structured Response 🔴
4- Return the JSON to the UI to build it.
Our main problem in step 3. Here is my approach to solving this problem:
Step 1: Decide on the JSON structure you want to return.
First, you should know what you want!
Which JSON Structure do you want? So you can ask the model to get it. For example, in my case, I want something like this:
{
"titles": [
"Title 1",
"Title 2",
"Title 3",
"Title 4",
"Title 5"
]
}
Perfect, Step 1 Done ✅
Now, let’s create a Python script and continue to step 2
Step 2: Define the model
The easiest and most efficient way to build tools is to return a class or a Pydantic model that can be read and accessed easily in your code.
So, I created a Pydantic model that fits the JSON response that I want.
class TitlesModel(BaseModel): titles: List[str]
Step 2: Done ✅
Step 3: Create the base prompt
Now, let’s create a prompt that generates blog post titles based on a topic. I will keep things simple for this example, let’s say:
base_prompt = f"Generate 5 Titles for a blog post about the following topic: [{topic}]"
Step 3: Done ✅
Step 4: Convert the Pydantic model into an example JSON String
I created a simple Python function to automate the process of creating an example Text JSON based on the Pydantic model.
We will use this to pass to the LLM in Step 5, here is the Function:
def model_to_json(model_instance):
"""
Converts a Pydantic model instance to a JSON string.
Args:
model_instance (YourModel): An instance of your Pydantic model.
Returns:
str: A JSON string representation of the model.
"""
return model_instance.model_dump_json()
Very simple!
Then, we use this Function to generate the string representation of the Pydantic model.
json_model = model_to_json(TitlesModel(titles=['title1', 'title2']))
Step 4: Done ✅
Step 5: Post-optimize the prompt
Now, I will use prompt engineering techniques to force the model to generate the JSON we want within the response. Here is how I did it:
optimized_prompt = base_prompt + f'.Please provide a response in a structured JSON format that matches the following model: {json_model}'
It is just adding and telling the language model to generate a JSON that matches the JSON_model we generated in step 4.
Step 5: Done ✅
Step 6: Generate Response with Gemini
Now call Gemini API and generate a response with the optimized_prompt.
I created a simple function that does this so I can use it directly in my code. Here it is:
import google.generativeai as genai
# Configure the GEMINI LLM
genai.configure(api_key='AIzgxb0')
model = genai.GenerativeModel('gemini-pro')
#basic generation
def generate_text(prompt):
response = model.generate_content(prompt)
return response.text
Then, I call from my script this way:
gemeni_response = generate_text(optimized_prompt)
Then we will get something like:
Absolutely! Here's a JSON format representation of 5 engaging blog post titles for a Python programming blog:
JSON
{
"titles": [
"Python Tricks: 5 Hidden Gems You Might Have Missed",
"Mastering Python Data Structures: Level Up Your Coding",
"Debugging Python Code Like a Pro: Strategies and Tools",
"Project Inspiration: Build a Fun Web App with Python",
"Elegant Python: Writing Clean and Readable Code"
]
}
A combination of text and JSON in the response!
But the JSON is constructed the way we want, great!
Step 6: Done ✅
Step 7: Extract the JSON String
Now, I used regular expressions to extract the JSON string from the output.
Here is the Function I created:
def extract_json(text_response):
# This pattern matches a string that starts with '{' and ends with '}'
pattern = r'\{[^{}]*\}'
matches = re.finditer(pattern, text_response)
json_objects = []
for match in matches:
json_str = match.group(0)
try:
# Validate if the extracted string is valid JSON
json_obj = json.loads(json_str)
json_objects.append(json_obj)
except json.JSONDecodeError:
# Extend the search for nested structures
extended_json_str = extend_search(text_response, match.span())
try:
json_obj = json.loads(extended_json_str)
json_objects.append(json_obj)
except json.JSONDecodeError:
# Handle cases where the extraction is not valid JSON
continue
if json_objects:
return json_objects
else:
return None # Or handle this case as you prefer
def extend_search(text, span):
# Extend the search to try to capture nested structures
start, end = span
nest_count = 0
for i in range(start, len(text)):
if text[i] == '{':
nest_count += 1
elif text[i] == '}':
nest_count -= 1
if nest_count == 0:
return text[start:i+1]
return text[start:end]
Then I call it:
json_objects = extract_json(gemeni_response)
Now we have the JSON!
Step 7: Done ✅
Step 8: Validate the JSON
Before using the JSON, I validated it to ensure it matched the Pydantic model I wanted. This allows me to implement a retry mechanism in case of any errors.
Here is the Function I created:
def validate_json_with_model(model_class, json_data):
"""
Validates JSON data against a specified Pydantic model.
Args:
model_class (BaseModel): The Pydantic model class to validate against.
json_data (dict or list): JSON data to validate. Can be a dict for a single JSON object,
or a list for multiple JSON objects.
Returns:
list: A list of validated JSON objects that match the Pydantic model.
list: A list of errors for JSON objects that do not match the model.
"""
validated_data = []
validation_errors = []
if isinstance(json_data, list):
for item in json_data:
try:
model_instance = model_class(**item)
validated_data.append(model_instance.dict())
except ValidationError as e:
validation_errors.append({"error": str(e), "data": item})
elif isinstance(json_data, dict):
try:
model_instance = model_class(**json_data)
validated_data.append(model_instance.dict())
except ValidationError as e:
validation_errors.append({"error": str(e), "data": json_data})
else:
raise ValueError("Invalid JSON data type. Expected dict or list.")
return validated_data, validation_errors
Here is how I used it in the code:
validated, errors = validate_json_with_model(TitlesModel, json_objects)
Step 8: Done ✅
Step 9: Play with the Model!
If step 8 does not contain errors, we can convert the JSON to Pydantic again and play with it as we like!
Here is the Function that converts JSON back to Pydantic:
def json_to_pydantic(model_class, json_data):
try:
model_instance = model_class(**json_data)
return model_instance
except ValidationError as e:
print("Validation error:", e)
return None
Here is how I used it in my script:
model_object = json_to_pydantic(TitlesModel, json_objects[0])
#play with
for title in model_object.titles:
print(title)
You see, now I can access the titles easily with my code!
My Magical Approach!
Instead of going through all the steps every time you want to build a tool or write a script, I added all this as a single function in the SimplerLLM Library!
Here is how you can build the same blog title generator tool with SimplerLLM with a few lines of code:
from pydantic import BaseModel
from typing import List
from SimplerLLM.language.llm import LLM, LLMProvider
from SimplerLLM.language.llm_addons import generate_basic_pydantic_json_model as gen_json
llm_instance = LLM.create(provider=LLMProvider.GEMINI, model_name="gemini-pro")
class Titles(BaseModel):
list: List[str]
topic: str
input_prompt = "Generate 5 catchy blog titles for a post about SEO"
json_response = gen_json(model_class=Titles,prompt=input_prompt, llm_instance=llm_instance)
print(json_response.list[0])
All the steps are now compressed into one line:
json_response = gen_json(model_class=Titles,prompt=input_prompt, llm_instance=gemini)In this way, you can build AI tools way faster and focus on the tool idea, functionality, and prompt instead of dealing with Inconsistent JSONs.
What is more important is that with this approach, you are not restricted to a specific language model. For example, you can change this line:
llm_instance = LLM.create(provider=LLMProvider.GEMINI, model_name="gemini-pro")
To:
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4")
And you will be using another Model… It is really like magic. Isn’t it?
Complex JSON?
Ok, our example was a basic JSON with a list of strings. What if we have a combination of different data types or other complex JSON structures?
Does this approach still work?
I tested it with a different JSON, and it is working now.
Yeah, maybe with more complex or nested JSON, this will become more complicated and harder to handle.
However, the idea is to extract the JSON properly from the text, so it is about optimizing Step 7.

Still, I believe that this approach can be a good starting point for solving output consistency in Language models.
I will be more than happy if you share your thoughts and opinions, and maybe your tests if you do some.
This will help improve this project and make it easier for anyone to play with Language models and get exactly the response they want!
Waiting for your responses 😅
Happy Coding!
You are the best I love this! Keep going please
Thanks for taking complex concepts and simplifying them,please could you show how to create python applications that return consistent Json output using Gemini and third party API’s ?
Thanks, this blog post is about Gemini. I will be creating more tutorials soon
Another great from you Hasan! I appreciate your dedication to serving people!
Please fix the lines:
from SimplerLLM.langauge.llm import LLM, LLMProvider
from SimplerLLM.langauge.llm_addons import generate_basic_pydantic_json_model as gen_json
to “language.llm”
Thank you, I will